I've follow the guide I find on https://learnopengl.com/ and managed to render a triangle on the window, but this whole process just seems over complicated to me. Been searching the internet, found many similar questions but they all seem outdated and none of them gives a satisfied answer.
I've read the guide Hello Triangle from the site mentioned above which has a picture explaining the graphics pipeline, with that I got the idea about why a seemingly simple task as drawing a triangle shape on screen takes so many steps.
I have also read the guide Coordinate Systems from the same site, which tells me what is the "strange (to me) coordinate" that OpenGL uses (NDC) and why it uses that.
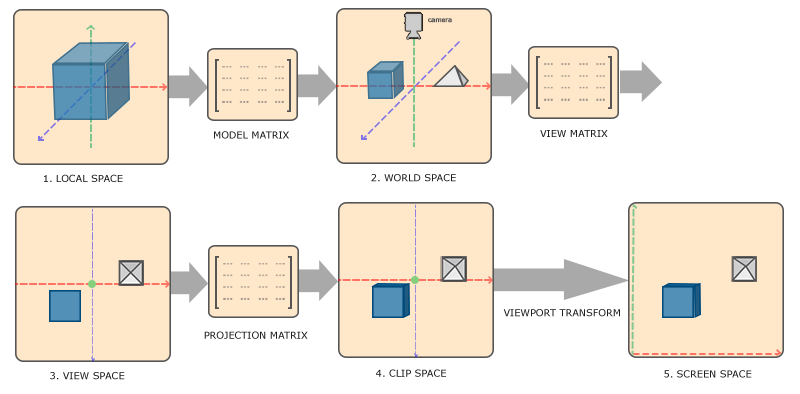
(Here's the picture from the guide mentioned above which I think would be useful for describing my question.)
The question is: Can I use the final SCREEN SPACE coordinates directly?
All I want is do some 2D rendering (no z-axis) and the screen size is known (fixed), as such I don't see any reason why should I use a normalized coordinate system instead of a special one bound to my screen.
eg: on a 320x240 screen, (0,0) represents the top-left pixel and (319,239) represents the bottom-right pixel. It doesn't need to be exactly what I describe it, the idea is every integer coordinate = a corresponding pixel on the screen.
I know it's possible to setup such a coordinate system for my own use, but the coordinates would be transformed all around and in the end back to screen space - which is what I have in the first place. All these just seems to be wasted work to me, also is't it gonna introduce precision lost when the coordinates get transformed?
Quote from the guide Coordinate Systems (picture above):
- After the coordinates are in view space we want to project them to clip coordinates. Clip coordinates are processed to the -1.0 and 1.0 range and determine which vertices will end up on the screen.
So consider on a 1024x768 screen, I define the Clip coordinates as (0,0) to (1024,678), where:
(0,0)--------(1,0)--------(2,0)
| | |
| First | |
| Pixel | |
| | |
(0,1)--------(1,1)--------(2,1) . . .
| | |
| | |
| | |
| | |
(0,2)--------(1,2)--------(2,2)
.
.
.
(1022,766)---(1023,766)---(1024,766)
| | |
| | |
| | |
| | |
(1022,767)---(1023,767)---(1024,767)
| | |
| | Last |
| | Pixel |
| | |
(1022,768)---(1023,768)---(1024,768)
Let's say I want to put a picture at Pixel(11,11), so the clip coordinates for that would be Clip(11.5,11.5) this coordinate is then processed to the -1.0 and 1.0 range:
11.5f * 2 / 1024 - 1.0f = -0.977539063f // x
11.5f * 2 / 768 - 1.0f = -0.970052063f // y
And I have NDC(-0.977539063f,-0.970052063f)
- And lastly we transform the clip coordinates to screen coordinates in a process we call viewport transform that transforms the coordinates from -1.0 and 1.0 to the coordinate range defined by glViewport. The resulting coordinates are then sent to the rasterizer to turn them into fragments.
So take the NDC coordinate and transform it back to screen coordinate:
(-0.977539063f + 1.0f) * 1024 / 2 = 11.5f // exact
(-0.970052063f + 1.0f) * 768 / 2 = 11.5000076f // error
The x-axis is accurate as 1024 is power of 2, but since 768 isn't so y-axis is off. The error is very little, but it's not exactly 11.5f, so I guess there would be some sort of blending happen instead of 1:1 representation of the original picture?
To avoid the rounding error mentioned above, I did something like this:
First I set the Viewport size to a size larger than my window, and make both width and height a power of two:
GL.Viewport(0, 240 - 256, 512, 256); // Window Size is 320x240
Then I setup the coordinates of vertices like this:
float[] vertices = {
// x y
0.5f, 0.5f, 0.0f, // top-left
319.5f, 0.5f, 0.0f, // top-right
319.5f, 239.5f, 0.0f, // bottom-right
0.5f, 239.5f, 0.0f, // bottom-left
};
And I convert them manually in the vertex shader:
#version 330 core
layout (location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos.x * 2 / 512 - 1.0, 0.0 - (aPos.y * 2 / 256 - 1.0), 0.0, 1.0);
}
Finally I draw a quad, the result is:

This seem to produce a correct result (the quad has a 320x240 size), but I wonder if it's necessary to do all these.
- What's the drawback of my approach?
- Is there a better way to achieve what I did?
It seems rendering in wireframe mode hides the problem. I tried to apply texture to my quad (actually I switched to 2 triangles), and I got different result on different GPU and non of them seem correct to me:
 Left: Intel HD4000 | Right: Nvidia GT635M (optimus)
Left: Intel HD4000 | Right: Nvidia GT635M (optimus)
I set GL.ClearColor to white and disabled the texture.
While both result fills the window client area (320x240), Intel give me a square sized 319x239 placed to the top left while Nvidia gives me a square sized 319x239 placed on the bottom left.
 This is what it looks like with texture turned on.
This is what it looks like with texture turned on.
The texture:
 (I have it flipped vertically so I can load it easier in code)
(I have it flipped vertically so I can load it easier in code)
The vertices:
float[] vertices_with_texture = {
// x y texture x texture y
0.5f, 0.5f, 0.5f / 512, 511.5f / 512, // top-left
319.5f, 0.5f, 319.5f / 512, 511.5f / 512, // top-right
319.5f, 239.5f, 319.5f / 512, 271.5f / 512, // bottom-right ( 511.5f - height 240 = 271.5f)
0.5f, 239.5f, 0.5f / 512, 271.5f / 512, // bottom-left
};
Now I'm completely stuck.
I thought I'm placing the quad's edges on exact pixel center (.5) and I'm sampling the texture also at exact pixel center (.5), yet two cards give me two different result and non of them is correct (zoom in and you can see the center of the image is slightly blurred, not a clear checker-board pattern)
What am I missing?
I think I figured out what to do now, I've posted the solutions as an answer and leave this question here for reference.


