I'm attempting to setup a practical Microservice demo for a few simple internal systems that deal with order management at my company, however I am struggling to understand that data consistency between Microservices when at scale.
I've identified a simple scenario for Microservices - a current application we have in play takes orders as they are processed on our website and updates a customers "Account Credit" - basically the outstanding money they can spend with us before their account needs to be reviewed.
I've attempted to break this VERY simple requirement down into a few Microservices. These are as defined below:
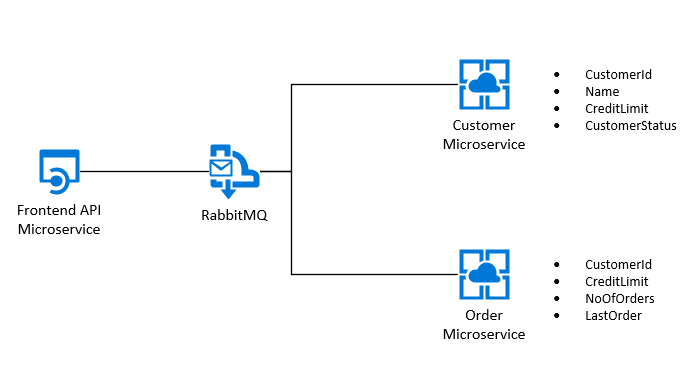
The API provides various differing levels of functionality - it allows us to create a new Customer, and this triggers the below:
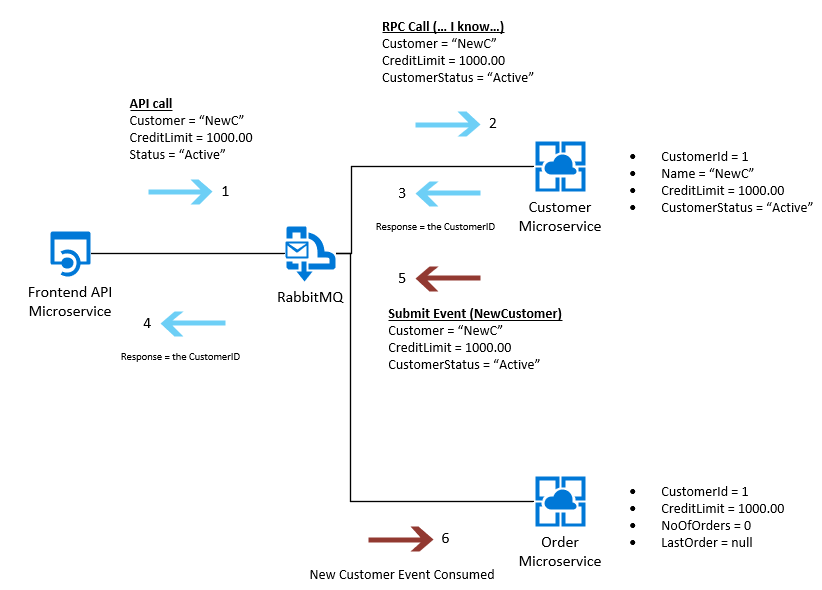
With SQL, we can do some optimistic queries when working within the database to try to ensure that when two orders are processed at the same time by scaling Microservices (EG: two instances of the Order Microservice, where each Microservice, but not each instance of a Microservice has its own database).
For example, we can do the following and assume SQL will manage locking, meaning that the number should end up at the right number when two orders are processed at the same time:
UPDATE [orderms].[customers] SET CreditLimit = CreditLimit - 100, NoOfOrders = NoOfOrders + 1 WHERE CustomerId = 1
With the above, if the credit was 1000 and 2 orders of 100 are processed, and each order is distributed to a different instance of the "Order" Microservice, we should be able to assume that the correct figures will be present in customers table within the Order Microservice (MSSQL query based locking should take care of this automatically).
The problem then comes when we attempt to integrate these back to the Customer Microservice.. We will have two messages, from each instance of the Order Microservice being passed as an event, example as below:
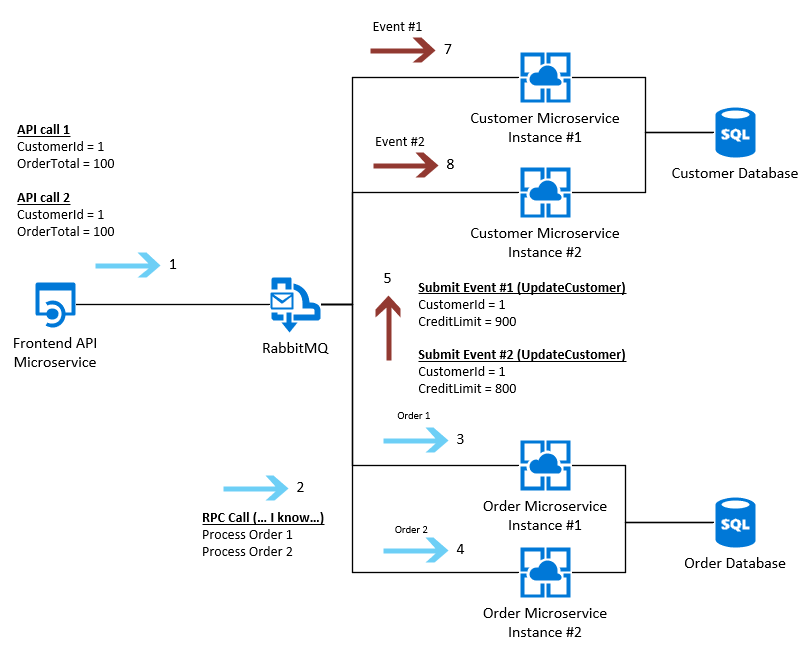
Given the above - it's likely we would follow the pattern of updating the "Customer" SQL table as per the following (these are the two queries):
UPDATE [customerms].[customers] SET CreditLimit = 900.00 WHERE CustomerId = 1
UPDATE [customerms].[customers] SET CreditLimit = 800.00 WHERE CustomerId = 1
However - based on the speed in which those "Customer" Microservices are running at, Instance #1 might be creating several new Customers at the moment, and therefore might process this request slower than Instance #2, which means the SQL queries would be executed out of order, and therefore we would be left with the "Order" database having a CreditLimit of 800 (correct) and the Customer Microservice with a CreditLimit of 900 (incorrect).
In a monolithic application, we would normally add an element of locking (or Mutex potentially) if this was really required, otherwise would rely on SQL locking as per the functionality within the Order Microservice, however as this is a distributed process, none of these older methods will apply.
Any advice? I can't seem to see past this somehow?
