SPARK Architecture:
Spark uses a master/worker architecture. There is a driver that talks to a single coordinator called master that manages workers in which executors run.

The driver and the executors run in their own Java processes. You can run them all on the same (horizontal cluster) or separate machines (vertical cluster) or in a mixed machine configuration.
Node are nothing but the physical machines.
Hadoop NameNode and DataNode:
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
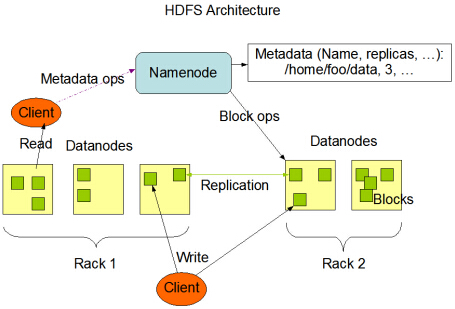
Yeah, DataNodes are the slave node in Hadoop cluster.
Please refer the documentation for more details.
