I need get dependencies in sentences from raw text using NLTK. As far as I understood, stanford parser allows us just to create tree, but how to get dependencies in sentences from this tree I didn't find out (maybe it's possible, maybe not) So I've started using MaltParser. Here is a peace code I'm using:
import os
from nltk.parse.stanford import StanfordParser
from nltk.tokenize import sent_tokenize
from nltk.parse.dependencygraph import DependencyGraph
from nltk.parse.malt import MaltParser
os.environ['JAVAHOME'] = r"C:\Program Files (x86)\Java\jre1.8.0_45\bin\java.exe"
os.environ['MALT_PARSER'] = r"C:\maltparser-1.8.1"
maltParser = MaltParser(r"C:\maltparser-1.8.1\engmalt.poly-1.7.mco")
class Parser(object):
@staticmethod
def Parse (text):
rawSentences = sent_tokenize(text)
treeSentencesStanford = stanfordParser.raw_parse_sents(rawSentences)
a=maltParser.raw_parse(rawSentences[0])
but last line throws exception "'str' object has no attribute 'tag'"
changing the code above like this:
rawSentences = sent_tokenize(text)
treeSentencesStanford = stanfordParser.raw_parse_sents(rawSentences)
splitedSentences = []
for sentence in rawSentences:
splitedSentence = word_tokenize(sentence)
splitedSentences.append(splitedSentence)
a=maltParser.parse_sents(splitedSentences)
throws the same exception.
So, what I'm I doing wrong. And in general: I'm I going in right way to get dependencies like this: http://www.nltk.org/images/depgraph0.png (but I need access these dependencies from code)
Traceback (most recent call last):
File "E:\Google drive\Python multi tries\Python multi tries\Parser.py", line 51, in <module>
Parser.Parse("Some random sentence. Hopefully it will be parsed.")
File "E:\Google drive\Python multi tries\Python multi tries\Parser.py", line 32, in Parse
a=maltParser.parse_sents(splitedSentences)
File "C:\Python27\lib\site-packages\nltk-3.0.1-py2.7.egg\nltk\parse\malt.py", line 113, in parse_sents
tagged_sentences = [self.tagger.tag(sentence) for sentence in sentences]
AttributeError: 'str' object has no attribute 'tag'

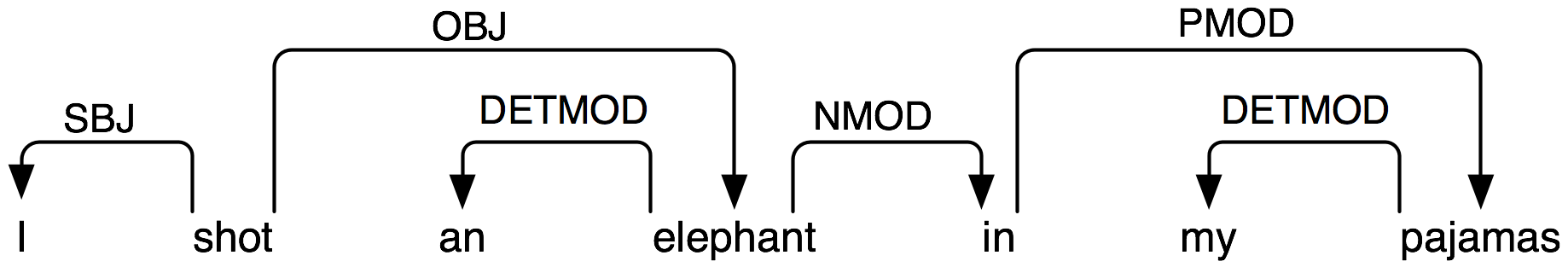{kind=link}