I have just started with familiarizing myself with SVM and have the following questions regarding SVMs and Kernels more specifically:
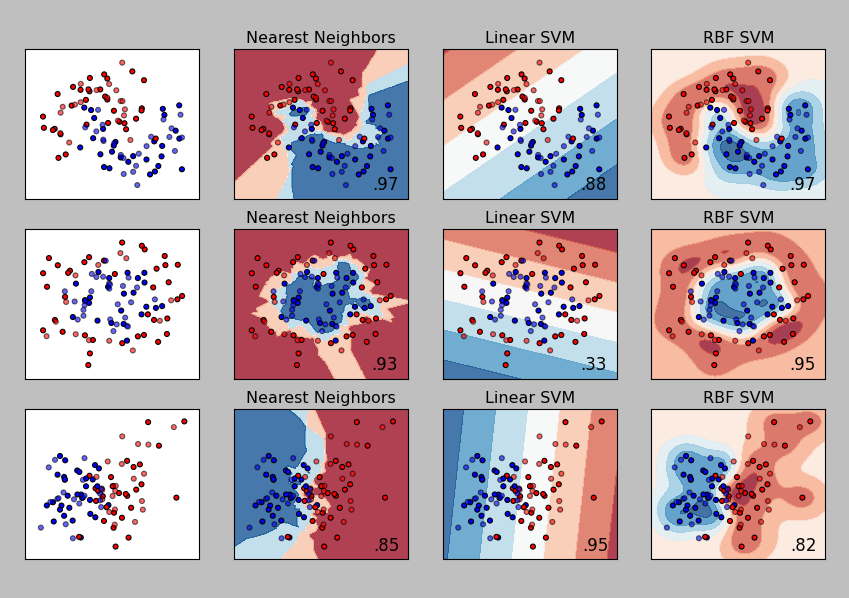
(1) If I understand the it correctly, the decision boundary is always linear. Kernels are used among others to map from the input space to the feature space, where possibly the previously linearliy not separatable data is now linearly separable. If the decision boundary is always linear though, how comes in some papers the talk is about "non linear decision boundaries" (e.g. in "A User's Guide to Support Vector Machines" by Ben-Hur et al., page 3)?
(2) Is there a possibility to know which Kernel to apply for which dataset, i.e. indications which Kernel might lead to linear separability in the feature space?
(3) It is often stated that an advantage of using a Kernel is to reduce the computational complexity. Now given our map $\phi$ is as follows: $\phi(x)^T \phi(z)$ = $(x_1^2, \sqrt{2}x_1*x_2)^T(z_1^2, \sqrt{2}z_1*z_2,z_2^2)$ for the two-dimensional vectors x and z, and this map can be written as the kernel $(x^T*z)^2$. Is the computational advantage the reduced number of operations (e.g. multiplications) which have to be performed, and the fact that using the kernel implies using the dot product in the input space but not in the feature space?
(4) Is the reason why the Kernel contains a scalar multiplication of two input vectors following from the fact that the weight vector can be written as the function of the input vectors?
Any help appreciated...

{kind=link}