I am trying to teach my camera to be a scanner: I take pictures of printed text and then convert them to bitmaps (and then to djvu and OCR'ed). I need to compute a threshold for which pixels should be white and which black, but I'm stymied by uneven illumination. For example if the pixels in the center are dark enough, I'm likely to wind up with a bunch of black pixels in the corners.
What I would like to do, under relatively simple assumptions, is compensate for uneven illumination before thresholding. More precisely:
Assume one or two light sources, maybe one with gradual change in light intensity across the surface (ambient light) and another with an inverse square (direct light).
Assume that the white parts of the paper all have the same reflectivity/albedo/whatever.
Find some algorithm to estimate degree of illumination at each pixel, and from that recover the reflectivity of each pixel.
From a pixel's reflectivity, classify it white or black
I have no idea how to write an algorithm to do this. I don't want to fall back on least-squares fitting since I'd somehow like to ignore the dark pixels when estimating illumination. I also don't know if the algorithm will work.
All helpful advice will be upvoted!
EDIT: I've definitely considered chopping the image into pieces that are large enough so they still look like "text on a white background" but small enough so that illumination of a single piece is more or less even. I think if I then interpolate the thresholds so that there's no discontinuity across sub-image boundaries, I will probably get something halfway decent. This is a good suggestion, and I will have to give it a try, but it still leaves me with the problem of where to draw the line between white and black. More thoughts?
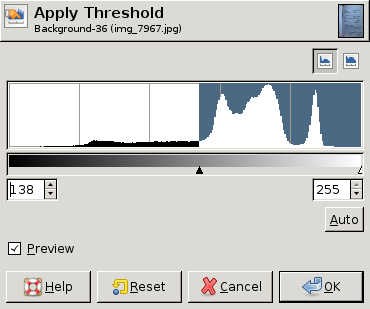
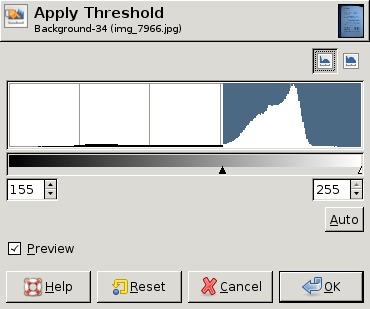
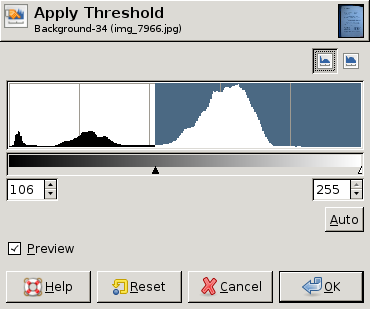
EDIT: Here are some screen dumps from GIMP showing different histograms and the "best" threshold value (chosen by hand) for each histogram. In two of the three a single threshold for the whole image is good enough. In the third, however, the upper left corner really needs a different threshold: