I know that this is a bit of an old post, but all of the regular expressions here are missing one very important component: the support for IDN domain names.
IDN domain names start with xn--. They enable extended UTF-8 characters in domain names. For example, did you know "♡.com" is a valid domain name? Yeah, "love heart dot com"! To validate the domain name, you need to let http://xn--c6h.com/ pass the validation.
Note, to use this regex, you will need to convert the domain to lower case, and also use an IDN library to ensure you encode domain names to ACE (also known as "ASCII Compatible Encoding"). One good library is GNU-Libidn.
idn(1) is the command line interface to the internationalized domain name library. The following example converts the host name in UTF-8 into ACE encoding. The resulting URL https://nic.xn--flw351e/ can then be used as ACE-encoded equivalent of https://nic.谷歌/.
$ idn --quiet -a nic.谷歌
nic.xn--flw351e
This magic regular expression should cover most domains (although, I am sure there are many valid edge cases that I have missed):
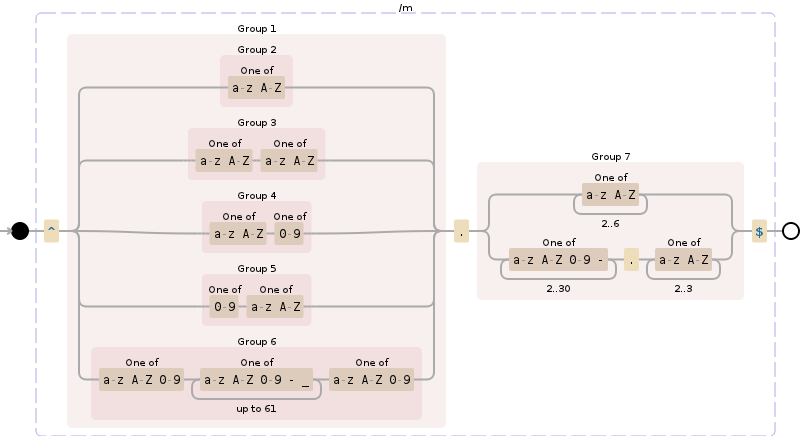
^((?!-))(xn--)?[a-z0-9][a-z0-9-_]{0,61}[a-z0-9]{0,1}\.(xn--)?([a-z0-9\-]{1,61}|[a-z0-9-]{1,30}\.[a-z]{2,})$
When choosing a domain validation regex, you should see if the domain matches the following:
- xn--stackoverflow.com
- stackoverflow.xn--com
- stackoverflow.co.uk
If these three domains do not pass, your regular expression may be not allowing legitimate domains!
Check out The Internationalized Domain Names Support page from Oracle's International Language Environment Guide for more information.
Feel free to try out the regex here: http://www.regexr.com/3abjr
ICANN keeps a list of tlds that have been delegated which can be used to see some examples of IDN domains.
Edit:
^(((?!-))(xn--|_{1,1})?[a-z0-9-]{0,61}[a-z0-9]{1,1}\.)*(xn--)?([a-z0-9][a-z0-9\-]{0,60}|[a-z0-9-]{1,30}\.[a-z]{2,})$
This regular expression will stop domains that have '-' at the end of a hostname as being marked as being valid. Additionally, it allows unlimited subdomains.